DigitalOcean doesn’t give their first-line support people the necessary tools to diagnose their own system problems. And so a two-day outage becomes possible.
The night before Christmas, I was scrambling to get my site back up
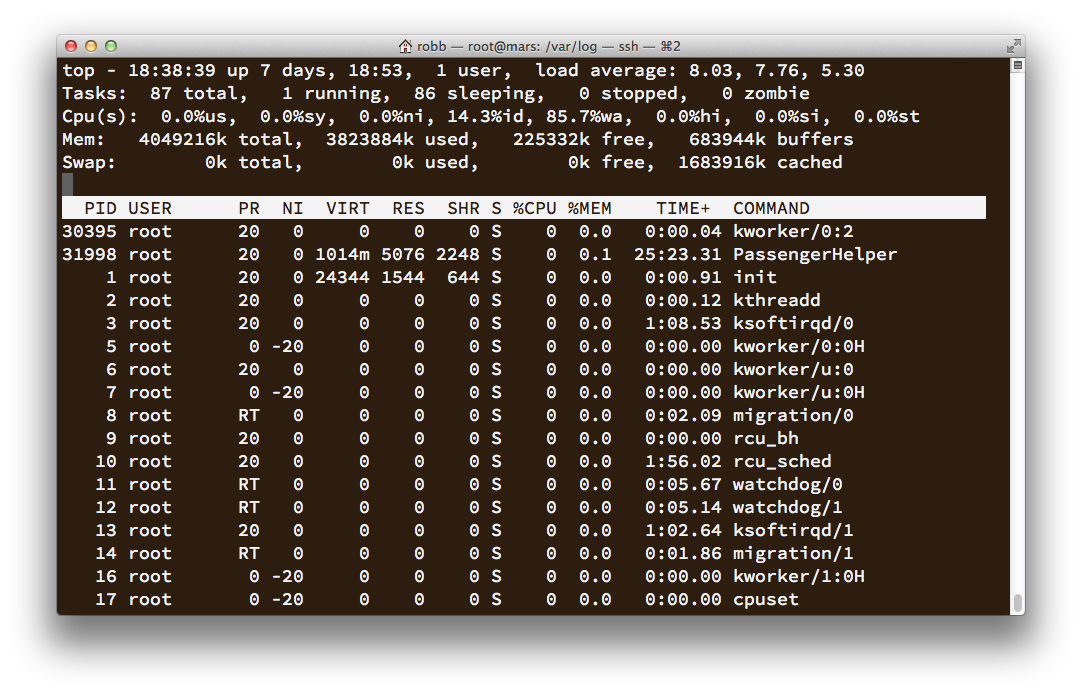
On the afternoon of the 24th, my New Relic monitor told me that weblaws.org (now public.law) was offline. Ugh. I ssh’d in to the 4GB RAM DigitalOcean Droplet and saw that the load was up to 8 (FYI, this is crazy high), although no processes were active, and it had a huge unexplainable “wait” time.
Then the server stopped responding entirely. I looked for an auto-backup (available for an extra 20% fee) but saw that all the recent ones had failed without explanation. I opened up a support ticket and included these screenshots.
The support person advised me to try logging in via the dashboard console to solve my problem. :-( That didn’t make sense given my question, but I gave it a shot, and the console app failed to connect.
Support next said that the problem was due to backups “producing too much I/O traffic”. But this also didn’t make sense: the server was still down, and completely inaccessible. I pointed this out, and my contact replied was that he would “escalate the ticket to our engineers…” I only then realized that the person who’d been providing “support” was only prepared with canned responses for trivial questions. They couldn’t actually diagnose or fix anything on their side.
This entire time, I was checking the Digital Ocean status page, and no outages were listed. I pinged them on Twitter, and they said that “everything looks good on their side”.
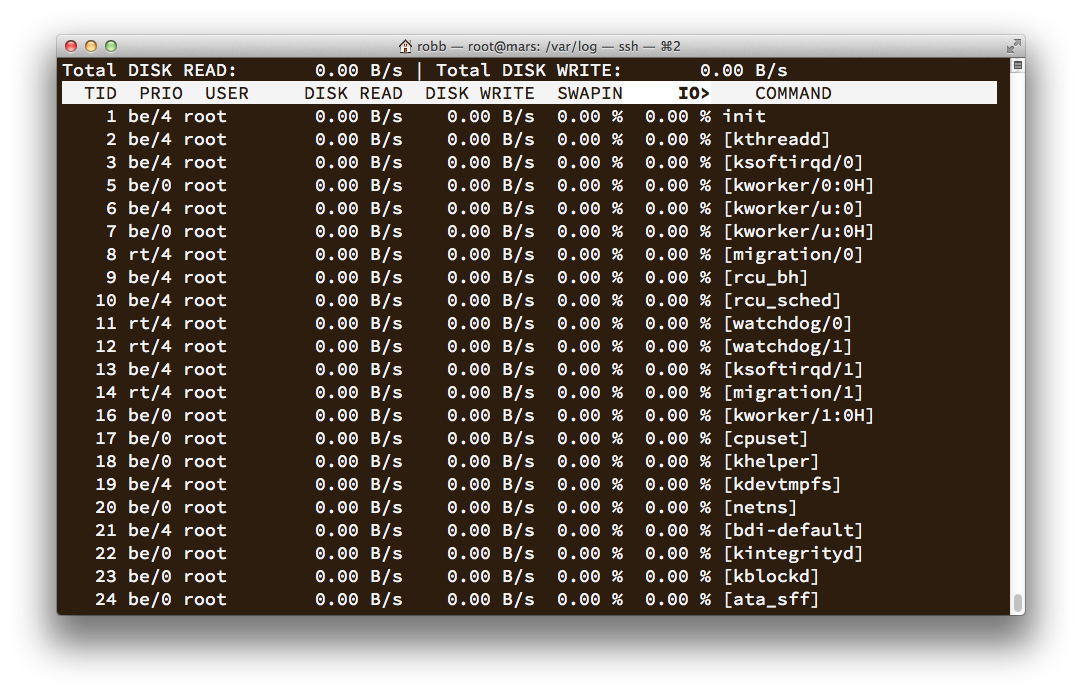
On the morning of the 26th, engineering responded, telling me that yes, there had been a problem with an underlying device causing outages, and it was now taken care of (although they hadn’t re-started my server). I logged in, was able to boot my Droplet, and – tada – it worked. But by this point, I had lost confidence in D.O., re-created the server at Linode, and so I canceled my D.O. account and requested a full refund.
Finally, they never updated their outage page to show the issue. (UPDATE, Jan. 7: the outage page still shows all ok for this time period.)
How Linode handles support
I’ve been with Linode since 2008 or so. Here’s how their support answers a ticket about a potential network problem.
Hello,
To further diagnose this issue, can you please provide us a pair of MTR reports between your current location and your Linode? We will need one from your current location to your Linode, and the reverse.
For information on generating an MTR report, please reference the following article:
http://library.linode.com/linux-tools/mtr
Additionally, if you are unable to connect to your Linode to provide the return report, you may use LISH to run this:
http://library.linode.com/troubleshooting/using-lish-the-linode-shell
Thanks,
Mark
Linode Support
Confidence inspiring.
Update, 12/27/2003.
Moisey Uretsky, a cofounder of Digital Ocean wrote to me apologizing for the problem and giving me a $100 credit. I appreciate that as well as the thoughtful letter, quoted below. I’m still skeptical about D.O.: for me the true problem seems to stem from the two-tiered support system they’ve implemented; not the actual technical problem.
Hi Robb,
I was reviewing the ticket you opened this week regarding the high load issue that you were experiencing on your droplet and our response. We definitely should have been reacting more pro-actively to the issue that you brought up.
The issue was caused by a hung state in one of our LVM processes and our monitoring was not setup to pick up that edge case. We have since escalated this issue to our DevOps team so that they add this event into the list of events that we monitor the nodes for.
This way if the event happens in the future it will trigger an immediate escalation to engineering so that it can be immediately resolved.
For security reasons our customer support staff does not have access to the hypervisors as this is strictly reserved for engineering only and even there we are constantly evaluating how we are performing code deploys and any administrative tasks to see how we can further lock down security.
In this case a lack of monitoring for this particular event, the fact that it was a holiday, and that the matter wasn’t escalated directly to engineering for resolution resulted in this issue persisting for your account for an inappropriate period of time.
We did want to say thank you for bringing this issue to our attention as we’ll be able to automate around this bug and ensure that it doesn’t impact customers in the future and for helping us find this bug we’ve also issued your account $100 credit which will remain indefinitely in case you happen to decide to use our services again in the future.
Thanks and Happy Holidays,
Moisey
Cofounder DigitalOcean

Leave a comment